Training a large language model is only the beginning of the story. After a model learns language from billions of examples during pretraining, engineers still need to make it more useful, safer, cheaper to run, and specialized for real-world applications.
This is where a handful of complementary techniques come in: Fine-Tuning, RLHF, LoRA, and Quantization. Each solves a different part of the problem — specialization, alignment, training cost, and deployment cost. Let’s walk through each one.
Fine-Tuning
Imagine a student who already understands mathematics broadly. Rather than relearning the subject from scratch, that student now focuses specifically on preparing for engineering entrance exams — building on existing knowledge rather than starting over.
Fine-tuning works the same way for AI models. A pretrained model already understands language, grammar, reasoning, and general knowledge. Instead of training an entirely new model, developers continue training the existing model on a smaller, more focused dataset relevant to a specific task or domain.
Common applications include:
- Medical AI assistants trained on clinical literature
- Legal document analyzers fine-tuned on case law
- Coding assistants specialized for a particular language or framework
- Financial chatbots trained on regulatory and market data
- Customer support systems tuned to a company’s specific products and tone
Fine-tuning meaningfully improves domain knowledge, produces more specialized and accurate responses, and makes a general-purpose model genuinely useful for a specific business context. The trade-off is cost — fine-tuning large models can require updating billions of parameters, which demands significant compute.
RLHF: Reinforcement Learning from Human Feedback
A language model can generate fluent text, but fluency alone doesn’t guarantee helpful or safe answers. This is the gap that RLHF is designed to close.
RLHF teaches a model how humans actually prefer responses to be framed — not just grammatically correct, but genuinely useful, polite, and aligned with what the person asking actually wants.
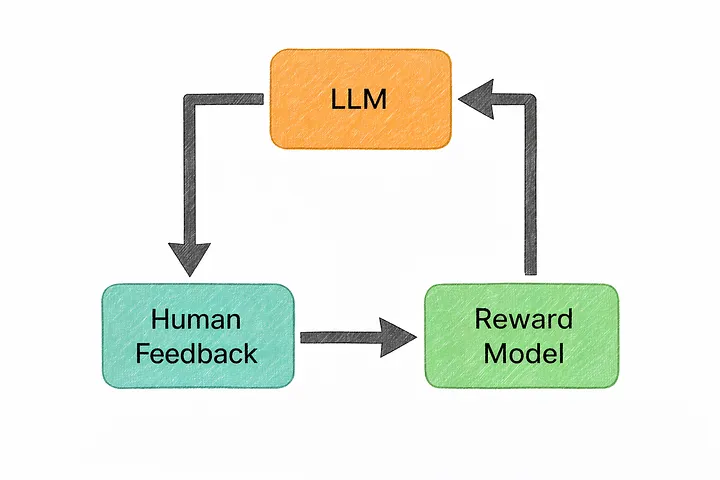
The process generally works like this:
- The model generates multiple candidate answers to the same prompt.
- Human evaluators compare these answers and rank them by quality.
- A reward model is trained to predict which responses humans tend to prefer.
- The original model is then fine-tuned using this reward signal, learning to favor the kinds of responses humans rated highly.
Consider two possible answers to the same question — one that’s technically accurate but confusing, and another that’s equally accurate but clear and well-structured. Human evaluators consistently choose the clearer answer, and over many rounds of this feedback, the model internalizes that helpfulness and clarity are what’s actually being rewarded.
This feedback loop is a major reason modern AI assistants feel conversational, helpful, and aligned with human expectations rather than just technically correct.
LoRA: Low-Rank Adaptation
Full fine-tuning of a large model can demand enormous computing resources, since it typically means updating every single parameter in the network. LoRA offers a far more efficient alternative.
Instead of modifying billions of existing parameters, LoRA freezes the original model entirely and adds a small number of new, trainable parameters alongside it. Think of it as attaching a small, specialized component to an existing machine rather than rebuilding the machine from scratch.
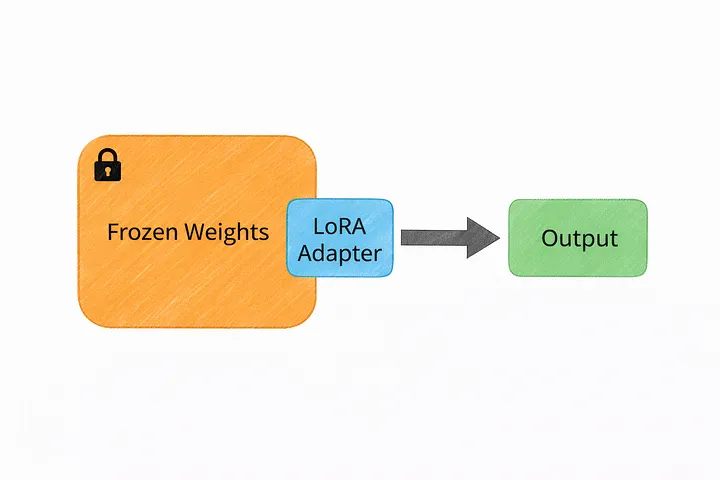
This approach offers several practical advantages:
- Significantly lower training cost
- Reduced GPU memory requirements
- Faster training cycles
- Much smaller storage footprint for each specialized version
- The ability to swap between different task-specific adapters on the same base model
Because of these benefits, LoRA has become a standard technique across the open-source AI ecosystem, making model customization accessible to teams without massive compute budgets.
Quantization
Modern AI models are large by design, often requiring substantial memory and powerful GPUs just to run. Quantization addresses this by reducing the numerical precision used to store a model’s weights — shrinking the model’s footprint with a carefully managed trade-off in precision.
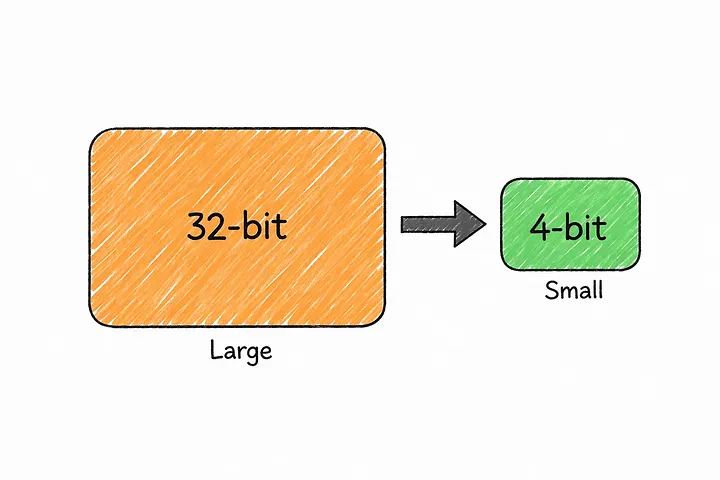
The practical benefits are significant:
- Reduced memory usage
- Faster inference speed
- Lower hardware requirements for deployment
- Cheaper hosting costs at scale
- The ability to run capable models on local, consumer-grade hardware
| Precision | Memory Usage |
|---|---|
| FP32 | Very High |
| FP16 | Medium |
| INT8 | Low |
| INT4 | Very Low |
Many local and on-device AI systems rely on 4-bit or 8-bit quantization specifically to make large models practical to run without specialized infrastructure.
Why These Techniques Matter Together
None of these techniques work in isolation — together, they form the practical pipeline that turns a research-grade language model into something deployable at scale:
- Fine-tuning makes a model specialized for a domain.
- RLHF makes a model genuinely helpful and aligned with human preferences.
- LoRA makes specialization affordable, even for smaller teams.
- Quantization makes deployment realistic on constrained hardware.
Training the base model is just the first step. The real engineering — and arguably the most impactful work — happens in this layer of optimization that sits between a raw pretrained model and a product people can actually rely on. Understanding these concepts gives you a much clearer picture of how today’s AI systems are built, and why they continue to get faster, cheaper, and more capable each year.