Every AI tool people use today — from ChatGPT to Claude and Gemini — is built on a series of breakthroughs that unfolded over several decades of research. It’s tempting to jump straight into Large Language Models without understanding the building blocks underneath them, but doing so often leaves a gap in intuition that makes everything else harder to follow.
Once you understand Neural Networks, Transfer Learning, Tokenization, Embeddings, Attention, and Transformers, modern AI becomes significantly easier to reason about — not as magic, but as a series of well-understood engineering ideas stacked on top of each other.
Neural Networks
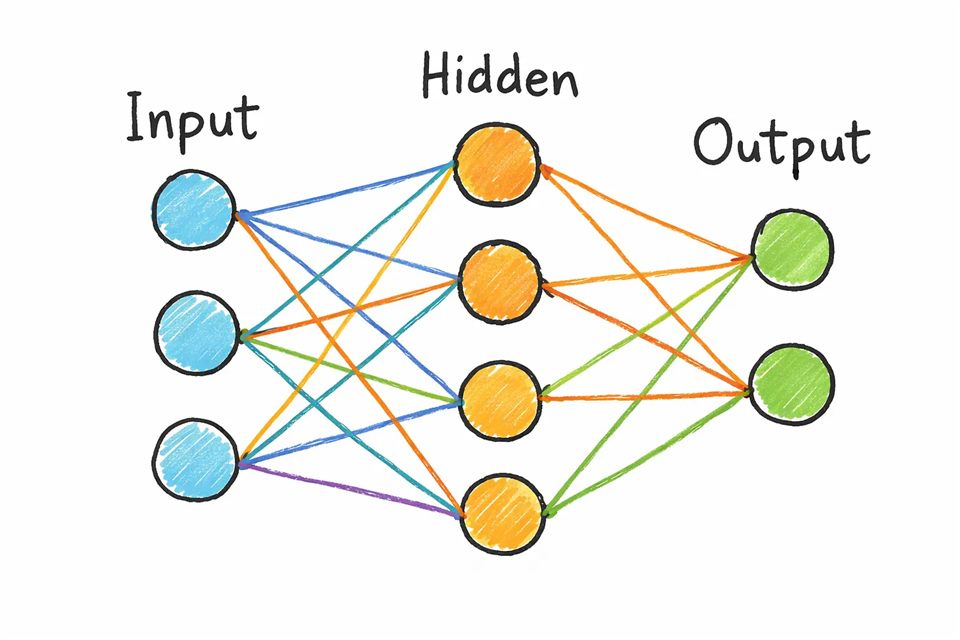
A neural network is the foundational building block of nearly all modern AI systems. It consists of layers of interconnected artificial neurons, organized so that information flows progressively through the network and gets transformed at each stage.
Information typically flows through three kinds of layers:
- Input layer — receives the raw data
- Hidden layers — extract increasingly abstract patterns
- Output layer — produces the final prediction or result
Each layer extracts progressively more meaningful structure from the data passed to it. An image recognition model, for example, might first detect simple edges in early layers, then recognize basic shapes in the middle layers, and finally identify complete objects by the time information reaches the output layer.

Transfer Learning
Training a large neural network completely from scratch is extremely expensive, both in compute and in the volume of data required. Transfer learning offers a far more practical path.
Instead of training a brand-new model for every new problem, developers start from a model that has already been pretrained on a large, general dataset, then adapt it to their specific use case. The model reuses the broad patterns and representations it already learned, rather than relearning everything from zero.
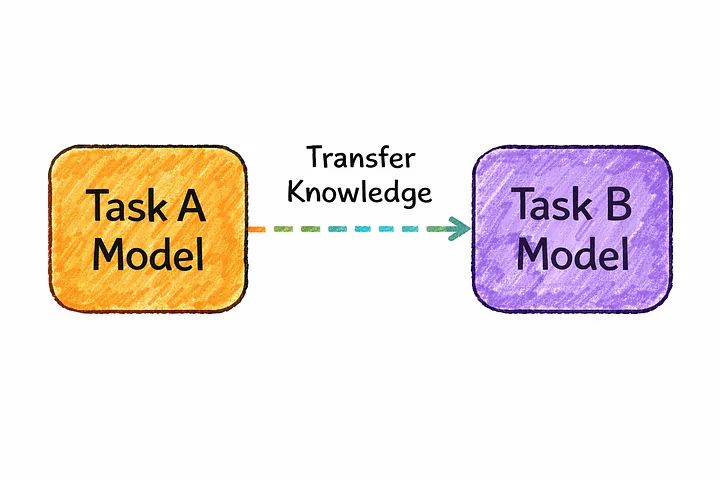
This single idea is the backbone of how most production AI products are built today — it’s dramatically faster and cheaper than training from scratch, and it consistently produces strong results even with relatively limited task-specific data.
Tokenization
AI systems don’t read text the way humans do. Before any model can process language, the text first needs to be broken down into smaller units called tokens.
Tokens can represent:
- Entire words
- Parts of words (sub-word units)
- Individual symbols and punctuation marks
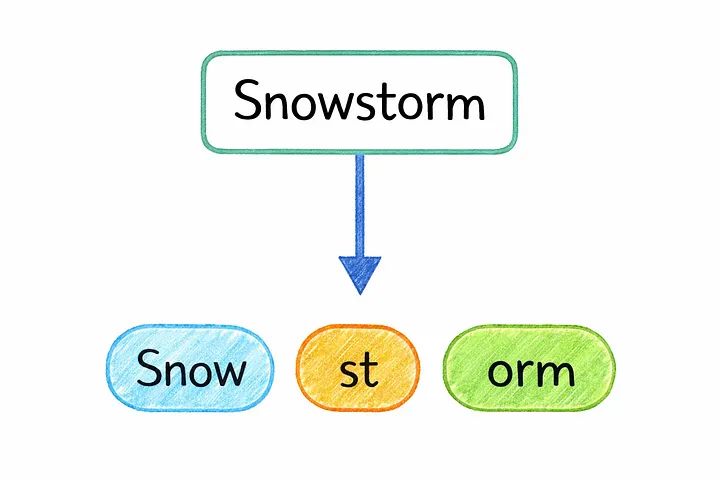
This sub-word approach lets models handle language far more efficiently than processing raw characters or whole words alone — it keeps vocabularies manageable while still being able to represent rare words, typos, and even multiple languages without needing a separate token for every possible word in existence.
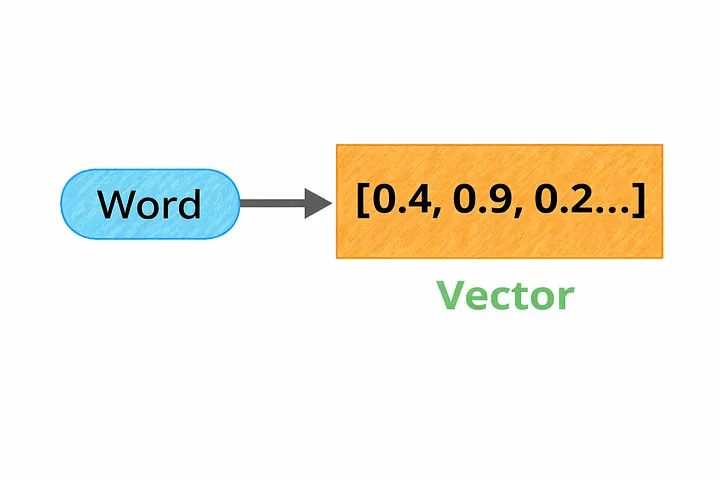
Embeddings
Once text is tokenized, each token needs to be converted into a format a neural network can actually work with: numbers. This is where embeddings come in — they convert words and tokens into dense numerical vectors.
These vectors aren’t arbitrary; they’re learned in a way that captures semantic meaning. Words with related meanings end up positioned close to each other in this vector space. For example:
- Doctor sits close to Nurse
- King sits close to Queen
This geometric structure is what allows AI systems to understand relationships between concepts — not by memorizing definitions, but by learning how words actually behave in relation to one another across enormous amounts of text.
Attention
Once a model has numerical representations of every token, it still needs to figure out which tokens matter most to each other in a given context. This is the role of the attention mechanism.
Attention helps a model determine which words in a sentence are most relevant when interpreting any other word. Consider this sentence:
She bought shares in Apple.
Without context, “Apple” could refer to the company or the fruit. Attention allows the model to weigh the influence of nearby words like “shares” and “bought” heavily enough to correctly infer that “Apple” refers to the company here, not the fruit.
This ability to dynamically focus on the most relevant parts of the input, rather than treating every word equally, is what gives modern language models their strong contextual understanding.
Transformers
The Transformer architecture, introduced in 2017, fundamentally changed the trajectory of AI research. Earlier architectures processed text sequentially, one token at a time, which made training slow and made it harder to capture relationships between distant words in a sentence.
Transformers instead process all tokens in a sequence simultaneously, using attention to relate every token to every other token directly — regardless of how far apart they are in the text.
This architectural shift brought several major benefits:
- Faster training — parallel processing instead of sequential steps
- Better long-range understanding — direct connections between distant tokens
- Massive scalability — the architecture that underlies every major LLM in use today
Every modern large language model — regardless of vendor — is built on some variation of this Transformer architecture.
Final Thoughts
Neural Networks, Transfer Learning, Tokenization, Embeddings, Attention, and Transformers aren’t separate, disconnected ideas — they’re layers that build directly on top of one another. Neural networks provide the basic learning mechanism, transfer learning makes that learning reusable, tokenization and embeddings give language a numerical form a model can work with, and attention combined with the Transformer architecture is what finally made today’s large-scale language models possible.
Without this stack of ideas, tools like ChatGPT simply wouldn’t exist. Understanding it doesn’t just satisfy curiosity — it gives you a much sharper lens for understanding why modern AI behaves the way it does, and where its real limitations come from.