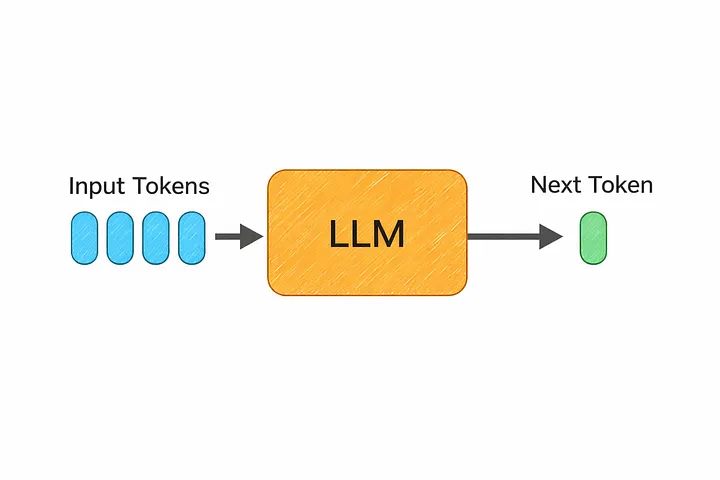
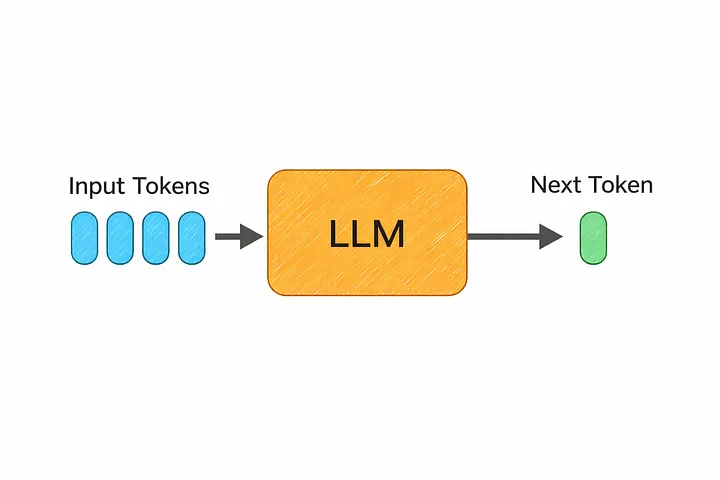
Large Language Models are among the most important breakthroughs in modern technology. They power the chat assistants, coding tools, and search experiences that millions of people use every day. Yet most people who use ChatGPT or similar tools have never seen what happens between typing a question and getting an answer.
This post walks through the core ideas behind LLMs in plain language — what they actually are, how they decide what to say next, and why they sometimes get things wrong.
What is an LLM?
At its core, an LLM is a Transformer-based neural network trained on a massive amount of text — books, articles, code, conversations, and more. The training objective behind it is surprisingly simple: given a sequence of text, predict the next token.
That single idea, repeated trillions of times across an enormous dataset, is what produces a system capable of writing essays, debugging code, and holding a conversation. The model never “memorizes” answers the way a database does. Instead, it learns statistical patterns in language that let it generate plausible, often genuinely useful, continuations of any text it’s given.
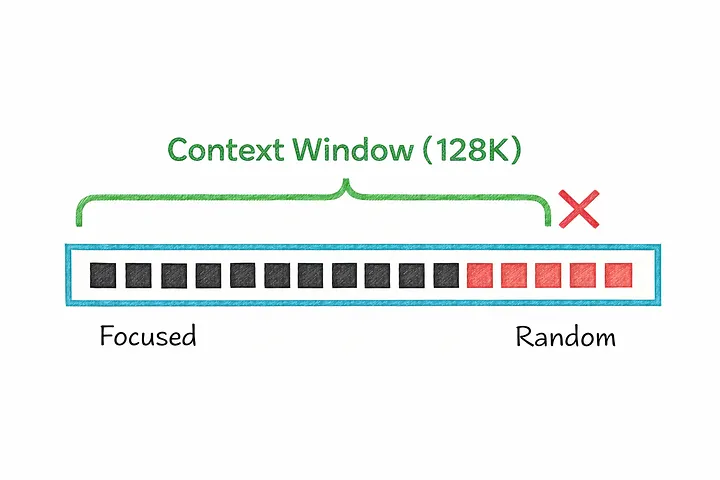
Context Window
Every language model has a limit to how much text it can consider at once. This limit is called the context window — it determines how much of the conversation, document, or codebase the model can actually “see” while generating a response.
Modern models can handle impressively large context windows, capable of processing:
- Long documents and research papers
- Extended multi-turn conversations
- Entire codebases or technical specifications
The trade-off is computational cost. A larger context window means more text to process for every single token generated, which directly increases the time and compute required to produce a response.
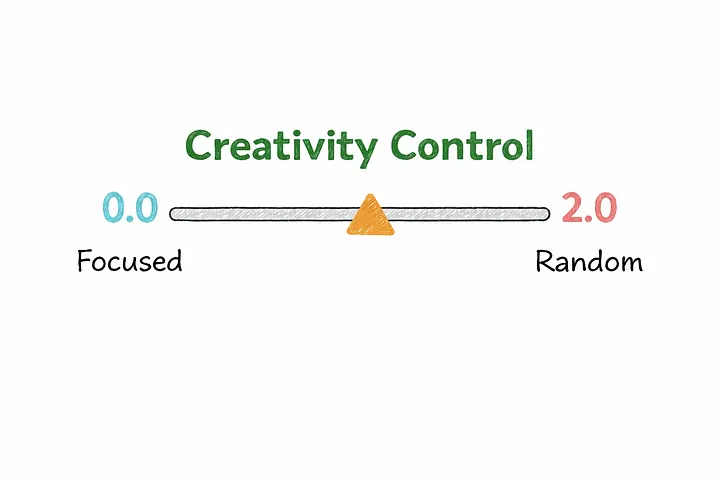
Temperature
Temperature is a setting that controls how predictable or creative a model’s output is.
Low temperature produces outputs that are:
- More predictable and consistent
- Better suited for coding and technical writing
- Ideal for factual analysis where accuracy matters most
High temperature produces outputs that are:
- More creative and varied
- Useful for brainstorming or creative writing
- Less predictable, since the model takes more risks in word choice
Choosing the right temperature is often a matter of matching the setting to the task — low for precision, higher for exploration.
Hallucinations
One of the most discussed limitations of LLMs is hallucination — when a model generates information that sounds completely plausible but is factually incorrect.
This happens because of how these models fundamentally work: they are optimized to predict likely-sounding text, not to verify facts against a ground truth. A model has no built-in mechanism to “look something up” unless it’s explicitly connected to external tools or data sources. This is precisely why techniques like Retrieval-Augmented Generation exist — to ground a model’s answers in verified information rather than relying purely on what it learned during training.
Step-by-Step Reasoning
Some questions can’t be answered correctly in a single leap — they require working through several intermediate steps before arriving at a final answer. This is especially true for math problems, logical puzzles, and multi-part technical questions.
Modern LLMs can be guided to reason step by step, often called chain-of-thought reasoning: breaking a problem down into smaller pieces, working through each one in sequence, and only then producing a final answer. This approach noticeably improves accuracy on tasks that involve logic or multi-step calculation, because it gives the model room to “show its work” rather than jumping straight to a guess.
Why LLMs Matter
The impact of large language models extends far beyond chatbots. They have meaningfully changed how people work across:
- Software development — generating, explaining, and debugging code
- Education — acting as on-demand tutors for nearly any subject
- Research — summarizing papers and accelerating literature reviews
- Content creation — drafting, editing, and brainstorming at scale
- Customer support — handling routine queries instantly and consistently
Understanding how these systems actually work — their strengths, their limits, and the engineering choices behind them — is becoming a genuinely useful skill, whether you’re building with AI or simply using it more effectively.